Fremkomsten af generaliserede lineære modeller har gjort det muligt for os at oprette regressionsmodeller af data, når fordelingen af svarvariablen ikke er normal - for eksempel når din DV er binær. (Hvis du gerne vil vide lidt mere om GLiM'er, skrev jeg et ret omfattende svar her, hvilket kan være nyttigt, selvom sammenhængen er forskellig.) En GLiM, f.eks. en logistisk regressionsmodel antager, at dine data er uafhængige . Forestil dig f.eks. En undersøgelse, der ser på, om et barn har udviklet astma. Hvert barn bidrager med et datapunkt til undersøgelsen - de har enten astma eller ikke. Nogle gange er data dog ikke uafhængige. Overvej en anden undersøgelse, der undersøger, om et barn er forkølet på forskellige steder i løbet af skoleåret. I dette tilfælde bidrager hvert barn med mange datapunkter. På et tidspunkt kan et barn muligvis være forkølet, senere måske ikke, og senere senere kan det få en anden forkølelse. Disse data er ikke uafhængige, fordi de stammer fra det samme barn. For at kunne analysere disse data korrekt skal vi på en eller anden måde tage denne manglende uafhængighed i betragtning. Der er to måder: En måde er at bruge generaliserede estimeringsligninger (som du ikke nævner, så vi springer over). Den anden måde er at bruge en generaliseret lineær blandet model. GLiMM'er kan redegøre for ikke-uafhængigheden ved at tilføje tilfældige effekter (som @MichaelChernick bemærker). Således er svaret, at din anden mulighed er for ikke-normale gentagne foranstaltninger (eller på anden måde ikke-uafhængige) data. (I overensstemmelse med @ Macros kommentar skal jeg nævne, at generelle izedede lineære blandede modeller inkluderer lineære modeller som et specielt tilfælde og således kan bruges med normalt distribuerede data. Imidlertid betegner udtrykket konnoterer ikke-normale data.)
Opdatering: (OP har også spurgt om GEE, så jeg vil skrive lidt om, hvordan alle tre relaterer til hinanden .)
Her er en grundlæggende oversigt:
- en typisk GLiM (jeg bruger logistisk regression som det prototypiske tilfælde) lader dig modellere et uafhængigt binært svar som en funktion af kovariater
- en GLMM lader du modellerer et ikke-uafhængigt (eller grupperet) binært svar betinget af attributterne for hver enkelt klynge som en funktion af covariater
- GEE giver dig modeller populationsmiddelrespons for ikke-uafhængige binære data som en funktion af kovariater
Da du har flere forsøg pr. deltager, data er ikke uafhængige som du korrekt bemærker, "[t] rials inden for en deltager er sandsynligvis mere ens end sammenlignet med hele gruppen". Derfor skal du bruge enten en GLMM eller GEE.
Så spørgsmålet er, hvordan man vælger, om GLMM eller GEE ville være mere passende for din situation. Svaret på dette spørgsmål afhænger af emnet for din forskning - specifikt målet for de slutninger, du håber at komme med. Som jeg sagde ovenfor, med en GLMM fortæller betaerne dig om effekten af en enhedsændring i dine kovariater på en bestemt deltager i betragtning af deres individuelle egenskaber. På den anden side med GEE fortæller betaerne dig om effekten af en enhedsændring i dine kovariater på gennemsnittet af svarene fra hele den pågældende befolkning. Dette er en vanskelig skelnen at forstå, især fordi der ikke er nogen sådan skelnen med lineære modeller (i hvilket tilfælde de to er de samme).
En måde at forsøge at pakke dit hoved omkring dette er at forestille sig et gennemsnit over din befolkning på begge sider af ligetegnet i din model. For eksempel kan dette være en model: $$ \ text {logit} (p_i) = \ beta_ {0} + \ beta_ {1} X_1 + b_i $$ hvor: $$ \ text {logit} (p) = \ ln \ left (\ frac {p} {1-p} \ right), ~~~~~ \ & ~~~~~~ b \ sim \ mathcal N (0, \ sigma ^ 2_b) $$
Der er en parameter, der styrer svarfordelingen ($ p $, sandsynligheden med binære data) på venstre side for hver deltager. På højre side er der koefficienter for effekten af covariatet [s] og basislinjeniveauet, når covariatet [s] er lig med 0. Den første ting at bemærke er, at den faktiske skæring for et bestemt individ er ikke $ \ beta_0 $, men snarere $ (\ beta_0 + b_i) $. Men hvad så? Hvis vi antager, at $ b_i $ 'erne (den tilfældige effekt) normalt er fordelt med et gennemsnit på 0 (som vi har gjort), kan vi bestemt gennemsnitligt over disse uden problemer (det ville bare være $ \ beta_0 $) . Desuden har vi i dette tilfælde ikke en tilsvarende tilfældig effekt for pisterne, og deres gennemsnit er således kun $ \ beta_1 $. Så gennemsnittet af aflytningerne plus gennemsnittet af skråningerne skal være lig med logit-transformation af gennemsnittet af $ p_i $'erne til venstre, ikke sandt? Desværre nej . Problemet er, at der mellem disse to er $ \ text {logit} $, som er en ikke-lineær transformation. (Hvis transformationen var lineær, ville de være ækvivalente, hvorfor dette problem ikke forekommer for lineære modeller.) Følgende plot gør dette klart: 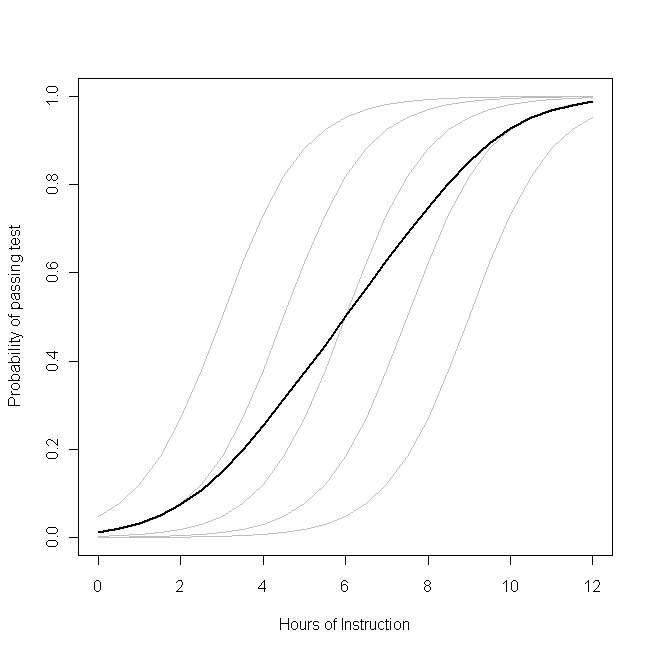
Forestil dig, at dette plot repræsenterer den underliggende datagenereringsproces for sandsynligheden for, at en lille klasse studerende vil være i stand til at bestå en test om et emne med et givet antal timers undervisning om dette emne. Hver af de grå kurver repræsenterer sandsynligheden for at bestå testen med forskellige instruktioner for en af de studerende. Den fedeste kurve er gennemsnittet over hele klassen. I dette tilfælde er effekten af en ekstra times undervisning betinget af elevens attributter $ \ beta_1 $ - den samme for hver elev (det vil sige, der er ikke en tilfældig hældning). Bemærk dog, at elevernes grundlæggende evne er forskellige blandt dem - sandsynligvis på grund af forskelle i ting som IQ (det vil sige, der er en tilfældig aflytning). Den gennemsnitlige sandsynlighed for klassen som helhed følger dog en anden profil end de studerende. Det slående kontraintuitive resultat er dette: En ekstra undervisningstime kan have en betydelig effekt på sandsynligheden for, at hver studerende består testen, men har relativt ringe effekt på den sandsynlige samlet andel af studerende, der består . Dette skyldes, at nogle studerende måske allerede har haft en stor chance for at bestå, mens andre stadig stadig har ringe chance.
Spørgsmålet om, hvorvidt du skal bruge en GLMM eller GEE, er spørgsmålet om, hvilke af disse funktioner du vil estimere. Hvis du ønskede at vide om sandsynligheden for, at en given studerende bestod (hvis du f.eks. var den studerende eller elevens forælder), vil du bruge en GLMM. På den anden side, hvis du vil vide om effekten på befolkningen (hvis du f.eks. Var lærer eller rektor), ville du gerne bruge GEE.
For en anden, mere matematisk detaljeret diskussion af dette materiale, se dette svar af @Macro.